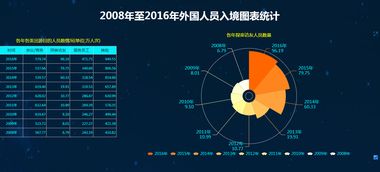
在數字化浪潮的推動下,數據處理服務已成為現代經濟和社會的核心驅動力。其中,邊緣計算作為新興產業的代表,與傳統數據中心形成了鮮明的對比與互補關系。本文將從數據處理模式、應用場景、技術特點及未來發展趨勢等方面,探討這兩者的異同與融合可能。
傳統數據中心是一種集中式的數據處理服務模式。它通常依賴大型服務器集群,將數據從各個終端設備傳輸到中心位置進行處理、存儲和分析。這種模式的優勢在于資源集中,便于管理和維護,能夠處理大規模、復雜的計算任務。例如,云計算平臺如AWS和阿里云就是典型代表,廣泛應用于企業級應用、大數據分析和人工智能訓練。傳統數據中心也存在延遲較高、帶寬消耗大等問題,尤其對于實時性要求高的應用,如自動駕駛或工業物聯網,難以滿足需求。
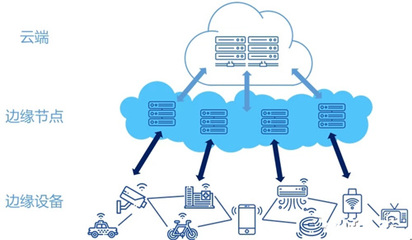
相比之下,邊緣計算作為一種新興技術,強調在數據產生的源頭或近源頭進行處理,即將計算資源部署在網絡邊緣,如智能設備、基站或本地網關。這種模式能夠顯著減少數據傳輸延遲,提高響應速度,并降低帶寬成本。例如,在智能制造中,邊緣計算可以實時分析傳感器數據,優化生產線效率;在智能城市中,它支持交通監控和緊急事件處理。邊緣計算的優勢在于其分布式架構,適用于高實時性、低延遲的應用場景,但也面臨著資源有限、管理復雜等挑戰。
從數據處理服務的技術特點來看,傳統數據中心更注重數據的集中存儲和深度分析,通常采用虛擬化和云計算技術,實現彈性擴展和高可用性。邊緣計算則側重于輕量級計算和實時決策,常結合人工智能算法,實現本地智能處理。兩者并非相互排斥,而是可以相互補充。例如,在混合架構中,邊緣節點處理實時數據,而傳統數據中心負責長期存儲和全局分析,形成“邊緣-云”協同的模式。
未來,隨著5G、物聯網和人工智能的普及,邊緣計算與傳統數據中心的融合將加速。這種融合將推動數據處理服務向更高效、智能的方向發展,例如在自動駕駛系統中,邊緣計算處理實時路況數據,而傳統數據中心提供歷史數據訓練模型。企業和開發者需要根據具體需求,選擇合適的架構,以優化性能、成本和可靠性。
邊緣計算和傳統數據中心各有優勢,共同構成了現代數據處理服務的生態系統。新興產業邊緣計算的崛起,并非取代傳統數據中心,而是通過協同創新,推動數字化時代的全面進步。對于用戶而言,了解這兩者的差異與聯系,有助于在技術決策中做出更明智的選擇。